
Confidence Intervals for Large Samples $(n >= 30)$
Q I ask $200$ randomly selected Hofstra students how much money they spent on Internet purchases over the past week. The sample mean for the $200$ students is $\$42.35.$ Therefore, I can make the follwing claim:
- Hofstra students spent an average of $\$42.35$ on Internet purchases last week.
right?
A Wrong. It could be the case that the $200$ students you selected just happened to be bigger Interenet spenders than the other Hofstra students. In fact, the average for all Hofstra students (the population mean) could be very different from the sample mean of $\$42.35.$ In fact, one can never know with absolute certainty even approximately wnat the population mean is. For instance, what if one student not polled happened to spend $\$10$ million on the Internet last week? The effect of including that student might be to raise the mean figure to over $\$1,000.$
Q OK then what is the point of taking a sample mean, since it tells us nothing?
A Slow down. It does not tell us nothing at all, it just gives no information with absolute certainty (unless, of course, our sample consists of the whole population). However, the larger the sample size, the more confident we can be that the population mean lies "fairly close" to the sample mean we obtained. This idea of "confidence" as oposed to "certainty" is what we will make precise here.
To understand what this is all about, you should know something about sampling distributions, where we learned about the
| Central Limit Theorem If the population distribution has mean μ and standard deviation $σ,$ then, for sufficiently large $n,$ the sampling distribution of $\bar{x}$ is approximately normal, with mean
$μ_{\bar{x}} = μ$
and standard deviation
$σ_{\bar{x}} =\frac{σ}{\sqrt{n}}.$
Notice that, as the sample size gets larger, the standard deviation gets smaller. Thus, the sample means tend to be very close to the population mean, resulting in a single, narrow peak at $μ$ as shown in the distribution curves below.
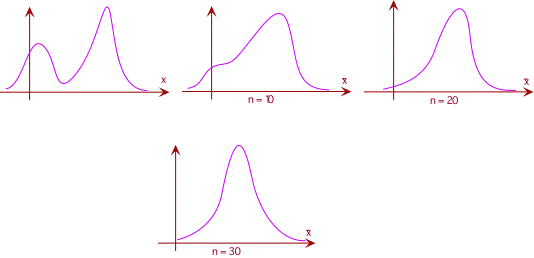
|
Note If the (population) distribution $X$ was already normal to begin with, then no matter what the sample size, the sampling distribution of $\bar{x}$ is exactly normal. Thus, the Central Limit Theorem is most useful for us only when the original distribution of $X$ is not known to be normal -- often the case in practice.
Q How large must the sample size $n$ be before the Central Limit Theorem "kicks in"?
A In principle, there is no way to know this, but for most practical purposes, people use the following rule of thumb: If $n > 30,$ then assume that n is sufficiently large, so that the sampling distribution is approximately normal.
Q OK what has this got to do with the original questoin about student spending on the Internet?
A Since the sample size was $n = 200$ students, the Central Limit Theorem tells us that the sample means ($\$42.35$ was one of those sample means) are approximately normally distributed. Now, from our knowledge about normal distributions, we can deduce:
| $95.45%$ of the sample means will lie within two standard deviations of the population mean (because $P(μ-2s ≤ \bar{x} ≤ μ+2s) = 0.9545)$ |
| Thus, |
| If we take a large number of sample means, $95.45%$ of the time, the distance between $\bar{x}$ and $μ$ will be less than two standard deviations (of the sampling distribution) -- that is, within a distance $2σ/\sqrt{n}$ of $n.$
|
| Or, |
| If we take a large number of sample means, $95.45%$ of the time, the (unknown) population mean is between
$\bar{x} - 2σ/\sqrt{n}$ and $\bar{x} + 2σ/\sqrt{n}.$
|
Thus, we call the interval $[\bar{x} - 2σ/\sqrt{n},$ $\bar{x} + 2σ/\sqrt{n}]$ the $95.45%$ confidence interval for the population mean.
Q OK. How do we get, say, the $90%$ confidence interval, or the $99%$ confidence interval?
A All we need to know is how many standard deviations about the mean will include $90%$ or $99%$ of the sample means. The following picture of the standard normal curve shows the $z-$value we want so that a total area of $0.90$ (or $90%$) is included between $z = -1.645$ and $z = 1.645:$
 We call this calue of $z$ $"z_{.05}"$ since the area of the tail to its right is $.05$ units, and we can use this value instead of $2$ in the above formula:
We call this calue of $z$ $"z_{.05}"$ since the area of the tail to its right is $.05$ units, and we can use this value instead of $2$ in the above formula:
$90%$ confidence interval $= [\bar{x} - 1.645σ/\sqrt{n},$ $\bar{x} + 1.645σ/\sqrt{n}]$
Similarly, for the $99%$ confidence interval, we can consult the following picture

and obtain:
$90%$ confidence interval $= [\bar{x} - 2.576σ/\sqrt{n},$ $\bar{x} + 2.576σ/\sqrt{n}]$
For a general formula, let us take $α =$ ($100% -$ percentage of confidence):
$α = 1.00 - 0.90 = 0.10$ $90%$ Confidence
$α = 1.00 - 0.99 = 0.01$ $99%$ Confidence
Then the interval we want is given by the following formula:
|
Large Sample $100(1-α)%$ Confidence Interval
$\bar{x} ± z_{α/2} \frac{σ}{\sqrt{n}}$
$\bar{x} =$ sample mean
$n =$ sample size
$σ =$ population standard deviation
$z_{α/2} = z-$value with an area of $α/2$ to its right (obtained from a table).
Note: When (as is often the case) we don't know the population standard deviation $σ,$ we can approximate it by the sample standard deviation $s,$ and obtain the following (good) approximation of the confidence interval:
$\bar{x} ± z_{α/2} \frac{s}{\sqrt{n}}$
|
Here is a little table of $z-$values:
| $\color{blue}{z_{.1}}$ | $\color{blue}{z_{.05}}$ | $\color{blue}{z_{.025}}$ | $\color{blue}{z_{.01}}$ | $\color{blue}{z_{.005}}$ | $\color{blue}{z_{.001}}$ | $\color{blue}{z_{.0005}}$ |
| $1.282$ | $1.645$ | $1.960$ | $2.326$ | $2.576$ | $3.090$ | $3.291$ |
Here is an example where you can put the above formula to use.
 Example 1 Hot Sauce
Example 1 Hot Sauce
Your hot sauce company rates its sauce on a scale of spiciness of 1 to 20. A sample of $50$ bottles of hot sauce is taste-tested, resulting in a mean of $12$ and a sample standard deviation of $2.5.$ Find a $95%$ confidence interval for the spiciness of your hot sauce.
Solution
Fill in the following values and press "Check" (don't "Peek" unless you absolutely have to...)
Q How do I interpret this confidence interval?
A It says that, if you repeatedly test $50-$bottle random samples of hot sauce and compute the confidence intervals each time, the confidence intervals you get will include the population mean $95%$ of the time. In that sense, there is a $95%$ chance that any specific confidence interval (such as the one above) actually contains the population mean. So, you can be $95%$ "certain" that the mean spiciness of your hot sauce is somwewhere between $11.307$ and $12.693.$
Following is a simulation that generates a number of random samples of size $n = 30$ from a uniformly distributed random variable taking values between $0$ and $1$ (mean $μ = 0.5$). For each sample, the mean and $90%$ confidence interval will be computed automatically. The standard deviation for a uniformly distributed random variable is given by $σ = (b-a)/\sqrt{12} = (1-0) /\sqrt{12} ≈ 0.2887.$
Each time a confidence interval is computed, it will be determined whether the interval comtains the mean. This should happen about $90%$ of the time.
Example 2 Illustration of Confidence Intervals
Pressing "Generate Samples" will give a window showing the indicated number of samples of size $n = 30$ together with the $90%$ confidence interval, and whether it contains the population mean $0.5.$ If you press "Generate Samples", approximately $90%$ of the confidence intervals given should contain the population mean of $0.5.$ Thus, you should average $18$ "yes"s for every $20$ samples.
Before we go on...Notice that, since the distribution we are sampling from is not normal (it is uniform), we need fairly large samples to guarantee that the distribution of the sample means is approximately normal -- assumed in our formulation of confidence intervals. Notice also that we use the theoretical population standard deviation in computing each interval rather than the sample standard deviation. We could have equally well have used the sample standard deviations instead.
Confidence Intervals for Small Samples $(n < 30)$
When we are dealing with small samples, we cannot invoke the Central Limit Theorem. Hence, we cannot use our formula for confidence intervals unless we are sampling from a normally distributed random variable.
However, there is one further issue: if we know the population standard deviation σ, then all is well and good, and we can go ahead and use the above formula for the confidence interval for small samples (assuming, of course that we are sampling from a normally distributed variable). But if, as is usually the case, we do not know $σ,$ then if we go ahead and use the sample standard deviation $s$ instead, we will tend to obtain confidence intervals that are too small. The reason is that, while the sampling distribution of $(\bar{x}-μ)/σ,$ is normal (provided $x$ is normal) the sampling distribution of $(\bar{x}- μ)/s$ is not normal (unless we are dealing with large samples, in which case it is approximately normal).
Q Why care about the sampling distribution of $(\bar{x}-μ)/s$?
A The reason we must care is that, when we use $s$ instead of $σ,$ then our computation of the confidence interval is based on the probability that $\bar{x}$ is within a certain number of standard deviations of the mean $μ.$ This number of standard deviations is $(\bar{x}-μ)/σ.$ We then set that equal to a desired $z-$value and solve for $\bar{x}$ to obtain the confidence interval (after dividing the standard deviation by $\sqrt{n}).$ When we use $s$ instead of $σ,$ we cannot use a $z-$value, since the distribution of $(\bar{x}-μ)/s$ is not normal, but is distributed according to the "$t-$distribution".
It follows that, instead of using $z_{α/2}$ in our formula, we need to use $t_{α/2}.$ Furthermore, we get different $t-$distributions for different sample sizes, and we use the value of $t_{α/2}$ corresponding to "$n-1$ degrees of freedom", which we can get from a table.
|
Small Sample $100(1-α)%$ Confidence Interval
When the Population Standard Deviation α is Known:
| $\bar{x} ± z_{α/2} \frac{σ}{\sqrt{n}}$ |
|
Same as Large Sample Formula |
$\bar{x} =$ sample mean
$n =$ sample size
$σ =$ population standard deviation
$z_{α/2} = z-$value with an area of $α/2$ to its right (obtained from a table).
When Only the Sample Standard Deviation $s$ is Known:
| $\bar{x} ± t_{α/2} \frac{s}{\sqrt{n}}$ |
|
We use $t$ instead of $z$ |
$\bar{x} =$ sample mean
$n =$ sample size
$s =$sample standard deviation
$t_{α/2} = t-$value with an area of $α/2$ to its right ($t_{α/2}$ can be obtained from a table here.).
|
Let us try this out on the following variant of the "Hot Sauce" Example above.
Example 3 More Hot Sauce
When the CEO of your hot sauce company was informed that the spiciness of the hot sauce averages only $12,$ he was furious and ordered instant adjustments to the recipe, threatening to fire the whole sauce division unless the average spiciness increased to above $13.$ Yesterday, you randomly sampled $8$ bottles of the new sauce and found an average spiciness of $13.5$ with a sample standard deviation of $0.75.$
(a) Compute the $95%$ confidence interval for the population mean. Based on the answer, can you be $95%$ sure that the mean spiciness of the new sauce is above $13$?
(b) Repeat part (a) assuming the sample standard deviation was $0.58.$
Solution
(a) Fill in the following values and press "Check".
(b) The calculation is almost identical to the one above, excpet for the value $s = 0.58,$ which gives the new confidence interval $[13.0150, 13.9850].$ Since this interval does not contain $13,$ we can be $95%$ certain that the mean spiciness of all the sauce is above $13.$
Last Updated:September, 2000
Copyright © 2000 StefanWaner and Steven R. Costenoble